How Pyth Pro Works
Understand the services that power Pyth Pro’s low-latency price delivery
Pyth Pro is a permissioned service that provides ultra-low-latency market data to consumers. It aggregates data from multiple publishers and distributes it to consumers through a multi-tier architecture.
Architecture Diagram
The following diagram illustrates the data flow through different components of Pyth Pro.
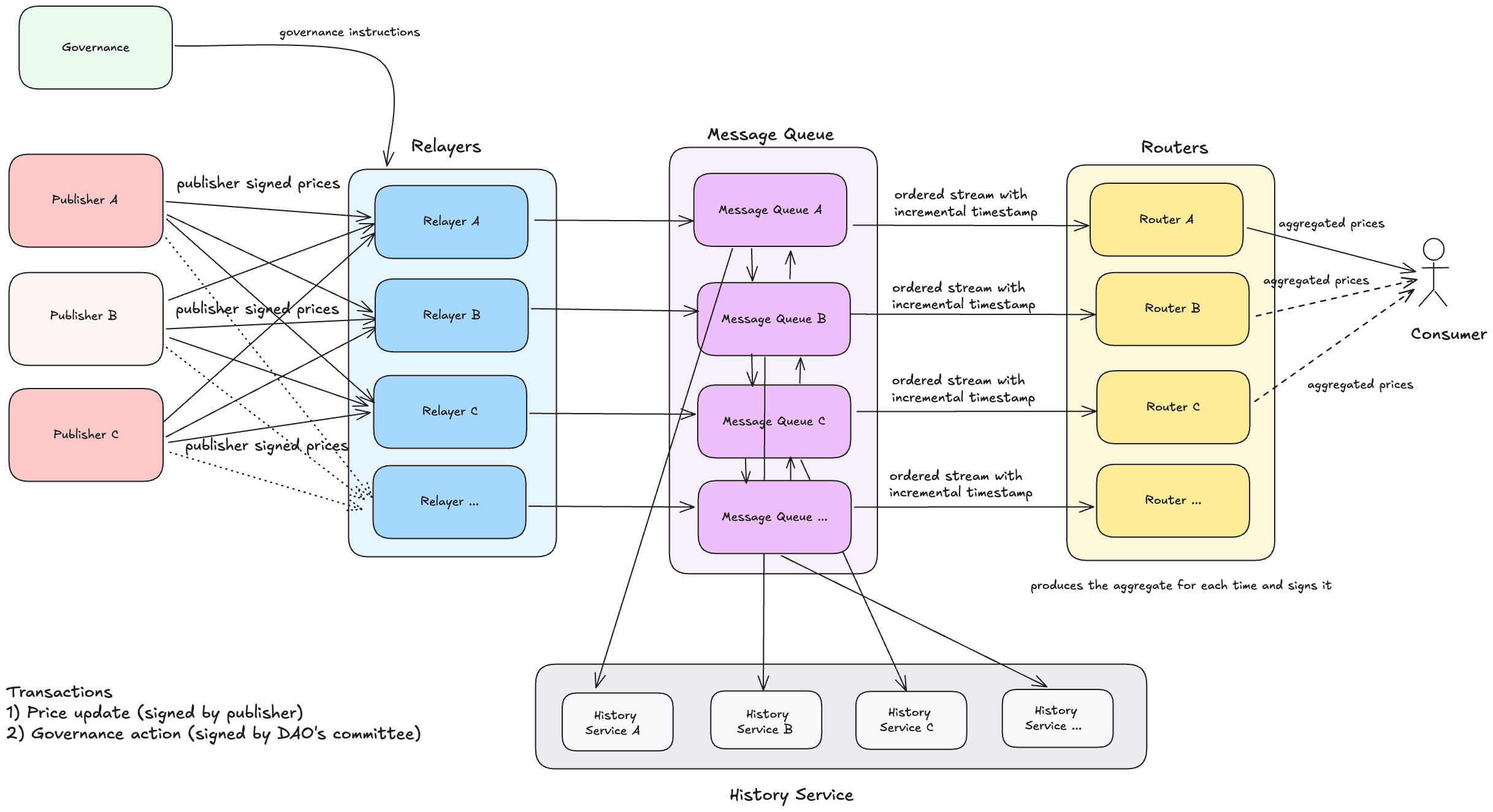
System Services
The architecture consists of five main types of services that work together to provide ultra-low-latency data to consumers. Each service has multiple instances running to ensure high availability and low latency.
Publishers
Publishers are the entities that provide market data to Pro. They submit updates via authenticated WebSocket connections. Each publisher is configured with specific permissions defining which feeds they can update.
Relayers
The Relayer service is the ingestion layer that receives and validates all incoming updates from publishers.
Key responsibilities:
- Authentication: Validates publisher access tokens and optional Ed25519 signatures.
- Validation: Performs sanity checks on incoming updates by examining feed IDs, timestamps, and values to ensure data integrity and proper formatting.
- Rate limiting: Enforces configurable limits on publisher updates.
- Message forwarding: Publishes validated updates to an internal message queue.
Douro Labs operates the relayer service for the Pyth Pro network. It follows a strict, deterministic processing model:
- No price dropping outside of circuit breakers: All validated updates are forwarded to the message queue without dropping any prices (except for when a circuit breaker is triggered).
- FCFS processing: Updates are processed on a first-come-first-served basis without prioritization.
This ensures reliable, predictable data flow from publishers to consumers.
Message Queue
The system uses a distributed message queue for pub/sub messaging with stream persistence. This allows the system to be deployed in a multi-datacenter environment and ensures reliable message delivery between services.
Message ordering: The message queue ensures reliable delivery and maintains the exact sequence of messages within each data stream. This means every publisher update will be delivered at least once, and messages will be processed in the same order they arrived at the Relayer. This sequential processing is essential for keeping all aggregators synchronized with the same feed state.
Routers
The Router is the real-time distribution layer that serves data to consumers. It embeds aggregation logic to compute median prices, confidence intervals (using interquartile range), and best bid/ask prices, funding rates, and more from multiple publisher inputs.
Key features:
- WebSocket streaming: Provides
/v1/streamendpoint for real-time price updates - HTTP REST API: Offers
/v1/latest_pricefor on-demand price queries - Channel types: Supports real-time and fixed-rate channels (50ms, 200ms, 1000ms)
- Multi-chain support: Generates on-chain payloads for Solana, EVM, and other chains
Aggregation logic
Each Router embeds an aggregator component that consumes publisher updates from the Message Queue and computes aggregated data feeds. The aggregator:
- Computes median values resistant to outlier data from individual publishers.
- Calculates confidence intervals using interquartile range to measure data spread.
- Determines best bid/ask values filtered to ensure market consistency.
- Automatically removes stale publisher data based on configurable timeouts.
Pro guarantees deterministic aggregation: all aggregators produce the exact same aggregated results by relying solely on the consistent stream of price updates from the Message Queue. This ensures that every Router instance maintains identical feed state, providing consistent data to all consumers regardless of which Router they connect to.
History Service
The History Service provides persistence and historical data queries.
Key responsibilities:
- Data persistence: Stores all publisher updates, aggregated data, and transactions.
- Historical queries: Provides REST API for querying historical data.
- OHLC API: Provides Open, High, Low, Close (OHLC) data for charting applications through the history service.